
Failure Classification
- Transaction failure
- Logical errors : 내부의 에러로 인해 트랜잭션이 완료하지 못한다.
- System errors : 데드락과 같은 시스템 에러 때문에 데이터베이스 시스템이 실행중인 트랜잭션을 종료해야 한다.
- System failure
- 휘발성 저장장치(volatile storage)의 유실되었을 때 문제가 발생한다.
- 전원 문제나 하드웨어/소프트웨어 실패는 시스템의 충돌을 일으킨다.
- Disk failure
- head 충돌이나, 유사한 disk 의 실패는 디스크 저장장치의 일부, 혹은 모든 부분에 영향을 미친다.
- 디스크 드라이브는 실패를 감지하기 위해 checksum 을 사용한다.
ex) 트랜잭션 T 가 A계좌에서 B계좌로 $50 를 이체한다고 생각해보자.
두 개의 업데이트가 일어날 것이다 -> A에서 $50 을 빼고, B에 $50이 추가된다.
이 때 둘 중 하나의 업데이트만 완료되고, 나머지 하나는 완료되지 않는다면 failure 가 발생한다.
-> 트랜잭션이 commit 하는 것을 보장하지 않고 데이터베이스를 수정하면 inconsistent 상태가 될 수 있다.
Recovery Algorithms
회복 알고리즘은 failure 가 발생하더라도 database consistency, transaction atomicity, durability 를 보장하는 기술이다.
보통 로그를 남김으로써 atomicity, consistency, durability 를 보장한다.
Storage Structure
- Volatile storage
시스템 충돌이 일어났을 때 보존되지 않는다.
ex) 메인 메모리, 캐시 메모리
- Nonvolatile storage
시스템 충돌이 일어났을 때도 보존된다.
ex) disk, tape, flash memory, non-volatile RAM (battery backed up)
- Stable storage
모든 실패에도 보존되는 형태의 이론적인 형태의 저장장치이다.
여러 개의 nonvolatile 장치 스토리지에 사본을 만들어 놓는다.
-> RAID 시스템을 사용한다.
Stable-Storage Implementation
분리된 여러 disk 들에 여러개의 복제본을 만들어 놓는다. 복제본들은 서로 다른 remote site 에 존재하여, 충돌이 일어났을 때 보존될 수 있다.
data tranfser 도중에 failure 가 발생하면 inconsistent 복제본이 생겨날 수 있다. 이에 대한 해결책은 다음과 같다.
- 첫 번째 block 에 정보를 저장한다.
- 첫 번째 block 에 저장이 완료되면 두 번째 block에도 저장한다.
- 두 번째 block 에도 저장이 되면 그제서야 완료된 것으로 간주한다.
-> 실제로는 RAID를 사용하여 보장한다.
RAID
과거 : 용량이 큰 디스크는 비싸니 싸고 용량이 적은 디스크를 여러개 구비하기 위해 사용되었다.
현재 : 더 높은 신뢰성, bandwidth 를 위해 사용된다. (독립성)
Level
- 0 : 중복 없음 -> 복사 안함
- 1 : 디스크 완전 복사
- 4 : block-interleaved parity
- 5 : block-interleaved distributed parity
Disk I/O should be atomic
disk i/o는 recovery 에 관해서 atomic 해야한다.
그치만 os 가 atomic I/O 를 지원하는 것은 쉽지 않기에, RAID 하드웨어로부터 쉽게 보장받을 수 있다.
-> checksum 을 통해 완전하지 않은 page output 을 발견할 수 있다.
Data Location
Data Block
- 디스크에 있는 블록을 물리적 블록(physical block)이라고 한다.
- 메인 메모리에 임시로 있는 블록을 버퍼 블록(buffer block)이라고 한다.
각 트랜잭션은 자신만의 고유 작업 공간이 있다.
- 모든 접근되고 갱신되는 데이터의 지역 사본은 이 공간에 있다.
디스크와 메모리 간의 블록 움직임
- input(B): physical block B를 메인메모리로 옮긴다. physical block은 디스크에 있는 블록이다.
- output(B): buffer block B를 disk로 옮기면서 적절한 physical block을 대체한다.
트랜잭션은 데이터를 시스템 버퍼 블록과 자신의 작업 공간 사이에 다음의 연산을 통해 주고 받는다.
- read(X): X에 해당하는 페이지가 버퍼 블록에 없다면, input(Bx)를 수행한다. 그리고 X에 buffer block 으로부터 값을 가져온다.
- write(X): X에 해당하는 페이지가 버퍼 블록에 없다면, input(Bx)를 수행한다. 그리고 buffer block 에 X 의 값을 업데이트한다. 이 후 적절한 시점에 disk write 를 한다. ( output(Bx) )
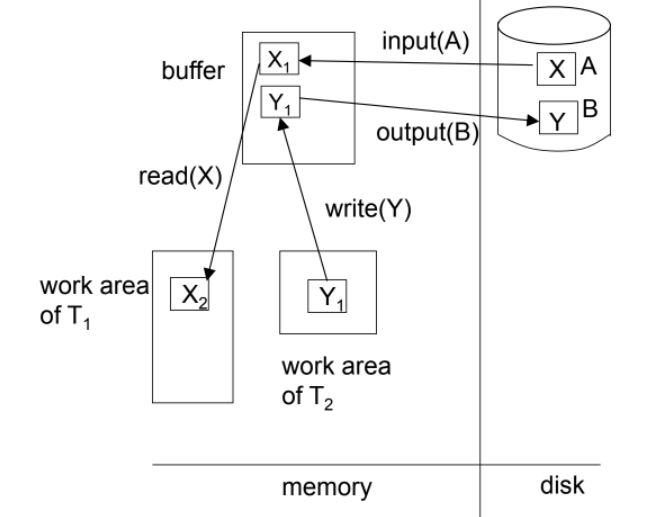
트랜잭션
- 트랜잭션은 처음으로 X의 값을 읽을 때, read(X)를 수행한다. -> buffer block 에 X에 해당하는 페이지를 가져온다.
- 모든 이후의 접근은 buffer block 을 통해서 이루어진다.
- 마지막 접근 후에는, update가 필요하다면 트랜잭션이 write(X)를 수행한다.
output(Bx)
- output(Bx)가 write(X) 다음에 바로 실행되는 것이 아니다.
- 시스템은 output 연산을 적절하다고 여길 때 수행한다.
* write(X) 이후에 바로 output(Bx)가 수행되지 않기 때문에, 이 사이에 system crash가 발생하면 X의 update가 디스크에 반영되지 않는다. 이 경우에도 데이터베이스 시스템은 consistency를 보장하기 위한 메커니즘을 구축해 두어야 한다.
'DB' 카테고리의 다른 글
| Log-Based Recovery (0) | 2022.04.21 |
|---|---|
| Logs (0) | 2022.04.21 |
| Insert and Delete Operations (0) | 2022.04.20 |
| Deadlock (0) | 2022.04.20 |
| Multiple Granularity Locking (0) | 2022.04.20 |

댓글